OpenEBS Storage Engines - cStor, Jiva and LocalPV
Overview of a Storage Engine
A storage engine is the data plane component of the IO path of a persistent volume. In CAS architecture, users can choose different data planes for different application workloads based on a configuration policy. A Storage engine can be hardened to optimize a given workload either with a feature set or for performance.
Operators or administrators typically choose a storage engine with a specific software version and build optimized volume templates that are fine-tuned with the type of underlying disks, resiliency, number of replicas, set of nodes participating in the Kubernetes cluster. Users can then choose an optimal volume template at the time of volume provisioning, thus providing the maximum flexibility in running the optimum software and storage combination for all the storage volumes on a given Kubernetes cluster.
Types of Storage Engines
OpenEBS provides three types of storage engines.
Jiva - Jiva is the first storage engine that was released in 0.1 version of OpenEBS and is the most simple to use. It is built in GoLang and uses LongHorn and gotgt stacks inside. Jiva runs entirely in user space and provides standard block storage capabilities such as synchronous replication. Jiva is suitable for smaller capacity workloads in general and not suitable when extensive snapshotting and cloning features are a major need. Read more details of Jiva here
cStor - cStor is the most recently released storage engine, which became available from 0.7 version of OpenEBS. cStor is very robust, provides data consistency and supports enterprise storage features like snapshots and clones very well. It also comes with a robust storage pool feature for comprehensive storage management both in terms of capacity and performance. Together with NDM (Node Disk Manager), cStor provides complete set of persistent storage features for stateful applications on Kubernetes. Read more details of cStor here
OpenEBS Local PV - OpenEBS Local PV is a new storage engine that can create persistent volumes or PVs out of local disks or host paths on the worker nodes. This CAS engine is available from 1.0.0 version of OpenEBS. With OpenEBS Local PV, the performance will be equivalent of either the local disk or the file system (host path) on which the volumes are created. Many cloud native applications may not require advanced storage features like replication or snapshots or clones as they themselves provide these features. Such applications require access to a managed disks as persistent volumes. Read more details of OpenEBS Local PV here
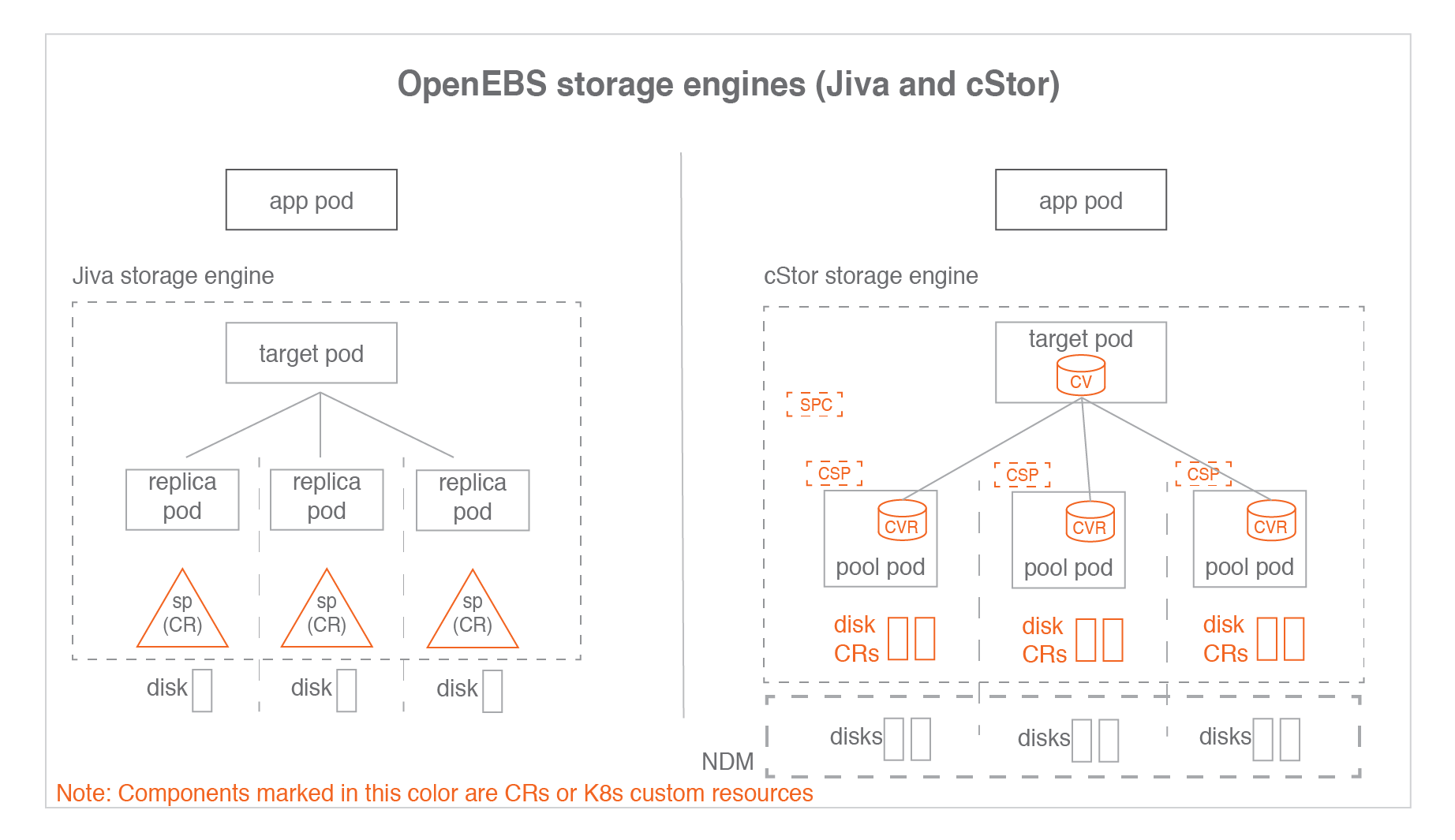
In the above figure:
SP - Storage Pool, the custom resource that represents the Jiva storage pool
CV - cStor Volume, the custom resource that represents the cStor volume
CVR - cStor Volume Replica
SPC - Storage Pool Claim, the custom resource that represents the cStor pool aggregate
CSP - cStor Storage Pool, the custom resource that represents cStor Pool on each node
One SPC points to multiple CSPs. Similarly one CV points to multiple CVRs. Read detailed explanation of cStor Pools here.
Choosing a storage engine
Storage engine is chosen by specifying the annotation openebs.io/cas-type in the StorageClass specification. StorageClass defines the provisioner details. Separate provisioners are specified for each CAS engine.
Sample spec - StorageClass for cStor
---
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: cStor-storageclass
annotations:
openebs.io/cas-type: cstor
cas.openebs.io/config: |
- name: StoragePoolClaim
value: "cStorPool-SSD"
provisioner: openebs.io/provisioner-iscsi
---
Sample spec - StorageClass for Jiva
---
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: jiva-storageclass
annotations:
openebs.io/cas-type: jiva
cas.openebs.io/config: |
- name: StoragePool
value: default
provisioner: openebs.io/provisioner-iscsi
---
When the cas-type is jiva , StoragePool value of default has a special meaning. When pool is default , Jiva engine will carve out the data storage space for the replica pod from the storage space of the container (replica pod) itself. When the size of the required volume is small (like 5G to 10G), StoragePool default works very well as it can be accommodated within the container itself.
Sample spec - StorageClass for LocalPV host path
---
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: localpv-hostpath-sc
annotations:
openebs.io/cas-type: local
cas.openebs.io/config: |
- name: BasePath
value: "/var/openebs/local"
- name: StorageType
value: "hostpath"
provisioner: openebs.io/local
---
Sample spec - StorageClass for LocalPV device
---
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: localpv-device-sc
annotations:
openebs.io/cas-type: local
cas.openebs.io/config: |
- name: StorageType
value: "device"
- name: FSType
value: ext4
provisioner: openebs.io/local
---
cStor vs Jiva vs LocalPV: Features comparison
Below table identifies few differences among the CAS engines.
| Feature | Jiva | cStor | LocalPV |
|---|---|---|---|
| Light weight and completely in user space | Yes | Yes | Yes |
| Synchronous replication | Yes | Yes | No |
| Suitable for low capacity workloads | Yes | Yes | Yes |
| Snapshots and cloning support | Basic | Advanced | No |
| Data consistency | Yes | Yes | NA |
| Backup and Restore using Velero | Yes | Yes | Yes |
| Suitable for high capacity workloads | Yes | Yes | |
| Thin Provisioning | Yes | No | |
| Disk pool or aggregate support | Yes | No | |
| On demand capacity expansion | Yes | Yes* | |
| Data resiliency (RAID support ) | Yes | No | |
| Near disk performance | No | No | Yes |
cStor is recommended most of the times as it commands more features and focussed development effort. cStor does offer robust features including snapshots/clones, storage pool features such as thin provisioning, on demand capacity additions etc.
Jiva is recommended for a low capacity workloads which can be accommodated within the container image storage, for example 5 to 50G. Even though there is no space limitations for using Jiva, it is recommended for a low capacity workloads. Jiva is very easy to use, and provides enterprise grade container native storage without the need of dedicated hard disks. Consider using cStor instead of Jiva especially when snapshots and clones capabilities are needed.
When to choose which CAS engine?
As indicated in the above table, each storage engine has it's own advantage. Choosing an engine depends completely on the application workload as well as it's current and future growth in capacity and/or performance. Below guidelines provide some help in choosing a particular engine while defining a storage class.
Ideal conditions for choosing cStor:
- When you want synchronous replication of data and have multiple disks on the nodes.
- When you are managing storage for multiple applications from a common pool of local or network disks on each node. Features such as thin provisioning, on demand capacity expansion of the pool and volume and on-demand performance expansion of the pool will help manage the storage layer. cStor is used to build Kubernetes native storage services similar to AWS EBS or Google PD on the Kubernetes clusters running on-premise.
- When you need storage level snapshot and clone capability.
- When you need enterprise grade storage protection features like data consistency, resiliency (RAID protection).
- If your application does not require storage level replication, using OpenEBS hostpath LocalPV or OpenEBS device LocalPV may be a better option. Check the conditions for choosing LocalPV.
Ideal conditions for choosing Jiva:
- When you want synchronous replication of data and have a single local disk or a single managed disk such as cloud disks (EBS, GPD) and you don't need snapshots or clones feature.
- Jiva is easiest to manage as disk management or pool management is not in the scope of this engine. A Jiva pool is a mounted path of a local disk or a network disk or a virtual disk or a cloud disk.
- Jiva is a preferred engine than cStor when
- Your application does not require snapshots and clones features.
- When you do not have free disks on the node. Jiva can be used on a
hostdirand still achieve replication. - When you do not need to expand storage dynamically on local disk. Adding more disks to a Jiva pool is not possible, so the size of Jiva pool is fixed if it on a physical disk. However if the underlying disk is a virtual or network or cloud disk then, it is possible to change the Jiva pool size on the fly.
- Capacity requirements are small. Large capacity applications typically require dynamic increase in the capacity and cStor is more suitable for such needs.
Ideal conditions for choosing OpenEBS hostpath LocalPV:
- When applications are managing replication themselves and there is no need of replication at storage layer. In most such situations, the applications are deployed as
statefulset. - When higher performance than Jiva or cStor is desired.
- hostpath is recommended when dedicated local disks are not available for a given application or dedicated storage is not needed for a given application. If you want to share a local disk across many applications host path LocalPV is the right approach.
Ideal conditions for choosing OpenEBS device LocalPV:
When applications are managing replication themselves and there is no need of replication at storage layer. In most such situations, the applications are deployed as
statefulsetWhen higher performance than Jiva or cStor is desired.
When higher performance than hostpath LocalPV is desired.
When near disk performance is a need. The volume is dedicated to write a single SSD or NVMe interface to get the highest performance.
Summary
A short summary is provided below.
- LocalPV is preferred if your application is in production and does not need storage level replication.
- cStor is preferred if your application is in production and requires storage level replication.
- Jiva is preferred if your application is small, requires storage level replication but does not need snapshots or clones.
See Also:
cStor User Guide
Jiva User Guide
Local PV User Guide
Feedback
Was this page helpful?
Thanks for the feedback. Open an issue in the GitHub repo if you want to report a problem or suggest an improvement. Engage and get additional help on https://kubernetes.slack.com/messages/openebs/.